PowerInfer-2: Fast Large Language Model Inference on a Smartphone
TL;DR
Today, we’re excited to introduce PowerInfer-2, our highly optimized inference framework designed specifically for smartphones. PowerInfer-2 supports up to Mixtral 47B MoE models, achieving an impressive speed of 11.68 tokens per second, which is up to 22 times faster than other state-of-the-art frameworks. Even with 7B models, by placing just 50% of the FFN weights on the phones, PowerInfer-2 still maintains state-of-the-art speed!
The speed in the video is not the fastest speed of powerinfer-2 because of overhead introduced by the rendering etc.
Background
The trend of deploying large models on mobile devices is rapidly gaining interest. Google has introduced AI Core, enabling the deployment of Gemini Nano on smartphones. Additionally, Apple has integrated a rumored 3B model in iOS 18. Various smartphone manufacturers are also exploring ways to implement large models on mobile devices to enhance data privacy and other benefits. However, the models currently runnable on mobile devices are relatively small and consume significant memory, severely limiting the application scenarios for large models.
Features
PowerInfer-2 is a high-speed inference engine for deploying activation-sparse LLMs for smartphones.
PowerInfer-2 is fast with:
-
Heterogenous computing: Decompose coarse-grained matrix computations into fine-grained “neuron clusters,” and then dynamically adjust the size of these clusters based on the characteristics of different hardware components.
-
I/O-Compute Pipeline: Neuron caching and fine-grained neuron-cluster-level pipelining techniques aim to maximize the overlap between neuron loading and computation.
See more technical details in PowerInfer-2 paper.
Evaluation
One notable advantage of PowerInfer-2 is its significant reduction in memory usage. To demonstrate the effectiveness of PowerInfer-2, we imposed various memory constraints on the TurboSparse-Mixtral model and compared the decoding speeds of PowerInfer-2, LLM in a Flash, and llama.cpp. The results clearly show that PowerInfer-2 significantly outperforms the other frameworks.

Another advantage of PowerInfer-2 is its improved inference speed. Whether in full in-memory scenarios or offloading scenarios, PowerInfer-2 significantly outperforms other frameworks, particularly on smartphones.
For 7B LLM, PowerInfer-2’s techniques can save nearly 40% of memory usage while achieving the faster inference speed as llama.cpp and MLC-LLM.
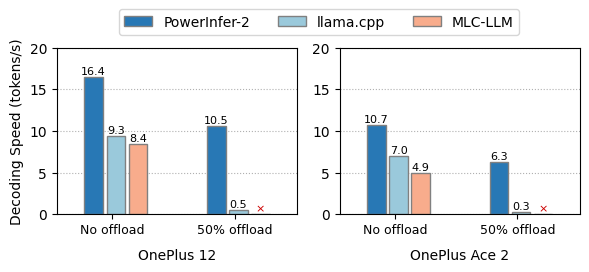
Decoding speeds of PowerInfer-2, llama.cpp, and MLC-LLM on TurboSparse-Mistral-7B with different offloading setups. “50% offload” means 50% model weights of FFN blocks are offloaded to flash storage. “No offload” means all model parameters are resident in memory. A red label of ⨉ indicates an execution failure due to the lack of weight offloading support.
Models
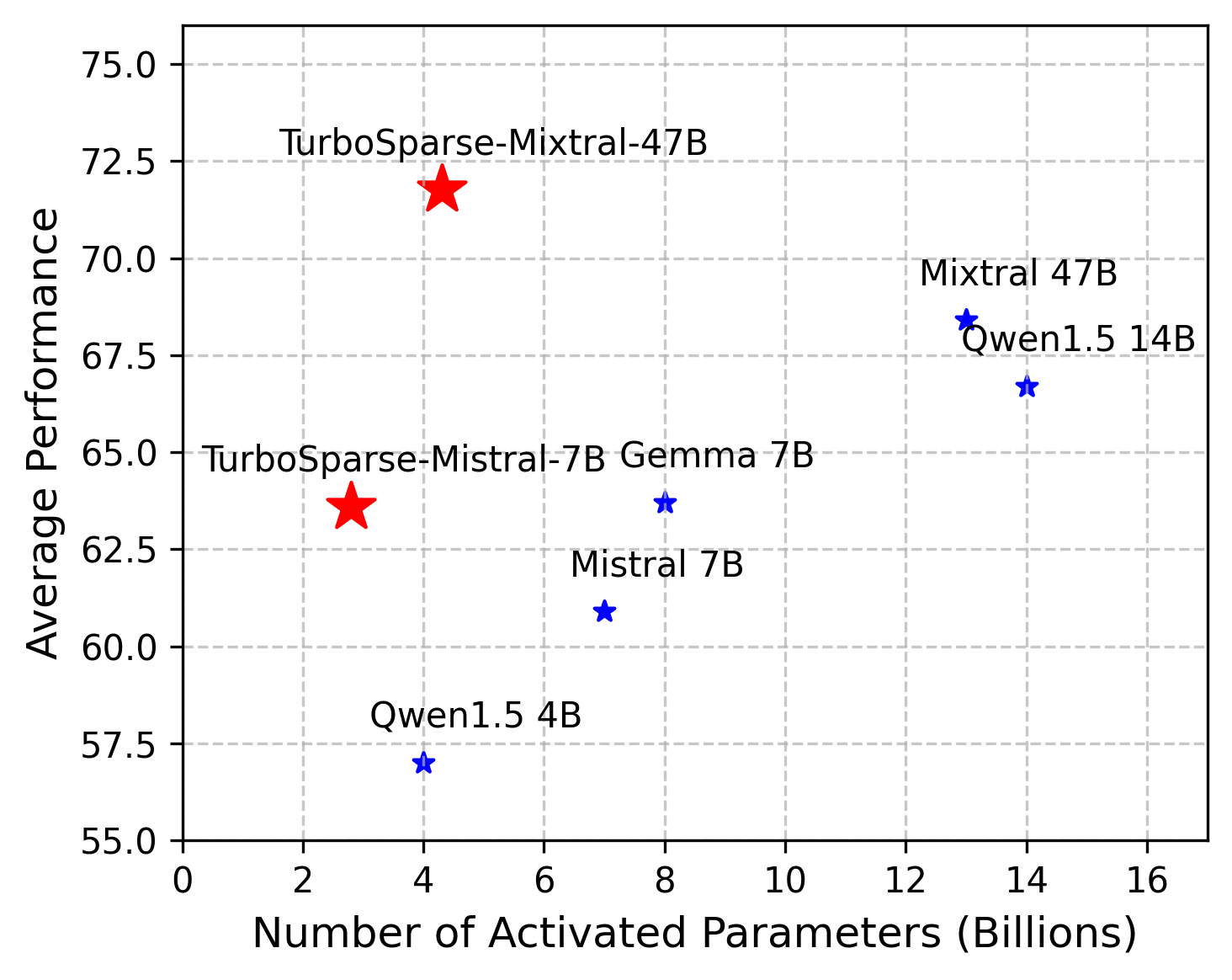
PowerInfer is a model-system co-design solution that requires strong predictable sparsity at the model level. Currently, mainstream models primarily use the SwiGLU structure, which does not exhibit strong predictable sparsity. To enhance this property, we have made certain modifications to the models.
We introduce two new models: TurboSparse-Mistral-7B and TurboSparse-Mixtral-47B. These models are sparsified versions of Mistral and Mixtral, respectively, ensuring not only enhanced model performance but also higher predictable sparsity. Notbly, our models are trained with just 150B tokens within just 0.1M dollars. Our models are release at https://huggingface.co/PowerInfer.
More technical details in our TurboSparse paper.